When it comes to privacy, it seems not all masks are sewn equal. While we’re deep in COVID’s 3rd wave in the United States, we’re getting renewed reminders of why wearing masks is not only critical for public health and safety, but also the added protection they have inadvertently brought to our privacy, especially in protest settings.
Are some fashion face masks better at preventing the detection of a face by a facial recognition system than others? How can we tell?
The Hunch:
As someone who designs surveillance-confounding fabrics I’ve felt blessed that, as we’ve found out from studies conducted to test the efficacy of existing systems, a facial-recognition confounding mask is mostly any mask properly worn on your face. And we know already from experiments run by NIST that color and coverage appears to matter:
“Wearing face masks that adequately cover the mouth and nose causes the error rate of some of the most widely used facial recognition algorithms to spike to between 5% and 50%, a study by the US National Institute of Standards and Technology (NIST) has found. Black masks were more likely to cause errors than blue masks.”
So we’re off to a good start with these results regarding black masks vs blue. But can I corroborate these results myself? What other colors or patterns might matter, especially if I’d like to pick a fashionable mask to match my favorite outfits?
Can we gather other information that might help people who aren’t computer vision researchers to infer what’s going on, so we can make decisions about how to better our chances of protecting ourselves from image recognition systems as we shop online?
Setting Up The Experiment:
I went to the website of one of my favorite custom clothing makers, and looked at their beautiful and varied mask selection. I gathered up about 400 photos of different styles of mask, including some that only cover the nose and mouth, some that covered the neck, some that were contoured, others pleated, many colors, and featured on models of different races and genders.








One benefit of working with a dataset of product images for retail clothing is that these photos are extremely consistent. For each of the models, the lighting, poses, and styling are similar, if not identical. Only the mask is typically the variant, so we have a lot of factors that are consistent from image to image. This will ideally help individual styles of mask stand out.
I used the instructions to run these 400 images through the OpenFace facial detection model in Python using this tutorial. I chose to use a pre-trained model and not train my own to better simulate the kinds of pre-trained systems that we are often most likely to encounter out in public spaces. Open source systems can be similar or even the exact same ones implemented by makers of both policing systems, and commercial technologies.
In tagging my test images set, I took note of general qualities of the image, like the mask style, which model it was on, the style of mask, whether the mask was light or dark toned, which I defined as more than 50% of the pattern being darker or lighter than mid-tone, or halfway between black and white.
The Results:
Of the 400 images run through a pre-trained model of OpenFace, a face was detected 25% of the time. This poor performance of this model in detecting faces with masks on is reflective of the same kinds of problems cited in the above NIST study.
This has us off to a good start but, confirming my hunch, it seemed some colors and patterns of masks appeared consistently were more permissive of facial detection than others. I’m going to show some below and let you see if you as the human can find a pattern between them.
















If you’re guessing that the masks that were lighter in color, and generally more likely to match a lighter-skinned person’s skin tone were more consistently detected by OpenFace, you were right.
In my experiment, models wearing lighter-toned masks made up 78% of the images that registered as containing a face.
Another 5% of the face-detected set were false positives, or when an object is detected that is not a face but a piece of hair or a fold of a shirt, or a small piece of fabric pattern. The dark-tone masked models were least likely to be detected by OpenFace, making up a scant 13% of all images that registered as having a face in them at all.
So, what might be going on here?
The Hunch, Part 2 (Electric Boogaloo):
Let’s revisit an important concept in color theory that can help us abstract what might be happening here. Colors are described as having a pure “hue” but adding black, white, or grey to that color creates different tints, tones, and shades as you can see below:

Many models of image recognition rely on finding contrast in an image to help define where a feature is, which then can be used to try and identify features similar enough to the training set to confirm that a new image contains (in this case) a face. Let’s look at what happened with some models photographed in the same pose, and same style mask, but different colors:

Certainly these masks are lighter in color, but we should check in particular why the blue, green, and red masks were still not considered light enough colors to detect as faces. We know black masks are very effective in blocking recognition, but it would be helpful to have a notion of why other colors can work too. So to check out the tones of these colors, we’re going to turn the whole image black and white.
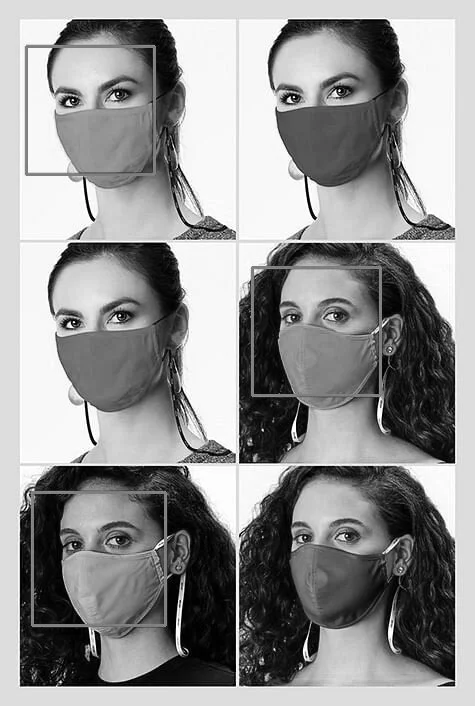
When the image is desaturated, we can see that some colors register as closer to our skin tone, or degree of lightness versus darkness, even if they are not the same hue. We could take a guess that having the entire face area be close enough to the tone the facial recognition system expects to see, might allow it to feel confident enough to detect a face even if the features that register to us as humans like a nose or a mouth are missing.
This has important implications for what we know to be the existing racial biases in training sets and models used for facial recognition technologies. If perhaps most of an image is made up of a tone expected to be seen on those typically white faces in a training set, the detection system may be more likely to see a face as well.
As I look to try similar at-home mini experiments in the future, I hope to find images of wider varieties of models, with a wider range of skin tones, ages, and hair styles, not just different color masks. It’s my hope that I could use these images to better assess what kind of masks may better work to block recognition of different kinds of people. If you find a data set of masked models that are a better representation of the public than the typically mono-racial and majority male ones we find online, and that may help in this kind of anti-surveillance research, please reach out at the contact page.
In order to help choose the mask that may be most likely to help you, especially as we can see how personal this is, you can do the following experiment at home.
How to pick a mask that may help you block facial recognition:
tl;dr version: Odds are you are looking for a mask that is likely not a lighter color, especially as these image recognition systems are, especially in their implementation in surveillance and commercial systems, more racially biased towards detecting lighter-skin faces.
The color you choose, regardless of hue (even if it’s blue, green, etc) should be different enough from your personal skin tone that the tones do not match in grayscale.
A great way to check whether a color matches your skin tone is to take a photo of your face with the mask on with your phone, open the image, then use your phone’s editing software to turn it black and white. In most phones this will be in the “Saturation” setting, where you can drag the toggle to black and white.
Remember: you’re looking to ensure that when both your skin and the mask are in grayscale, they don’t seem to match too closely. This isn’t a 100% guarantee no system can ever read in your face. But you can double-check your effort by opening Instagram, Snapchat, or even the camera in your phone to see if the built-in facial-detection functions have trouble identifying your masked face.

Screencaps of how to desaturate a photo in iOS
If you want extra insurance for your facial recognition-blocking intentions at the next protest you attend: add some sunglasses and a hat. Always great to be able to protect your health, your skin, and your privacy at the same time.